Finding Needles in a Paper Haystack
Oct 12, 2022 | 4 min read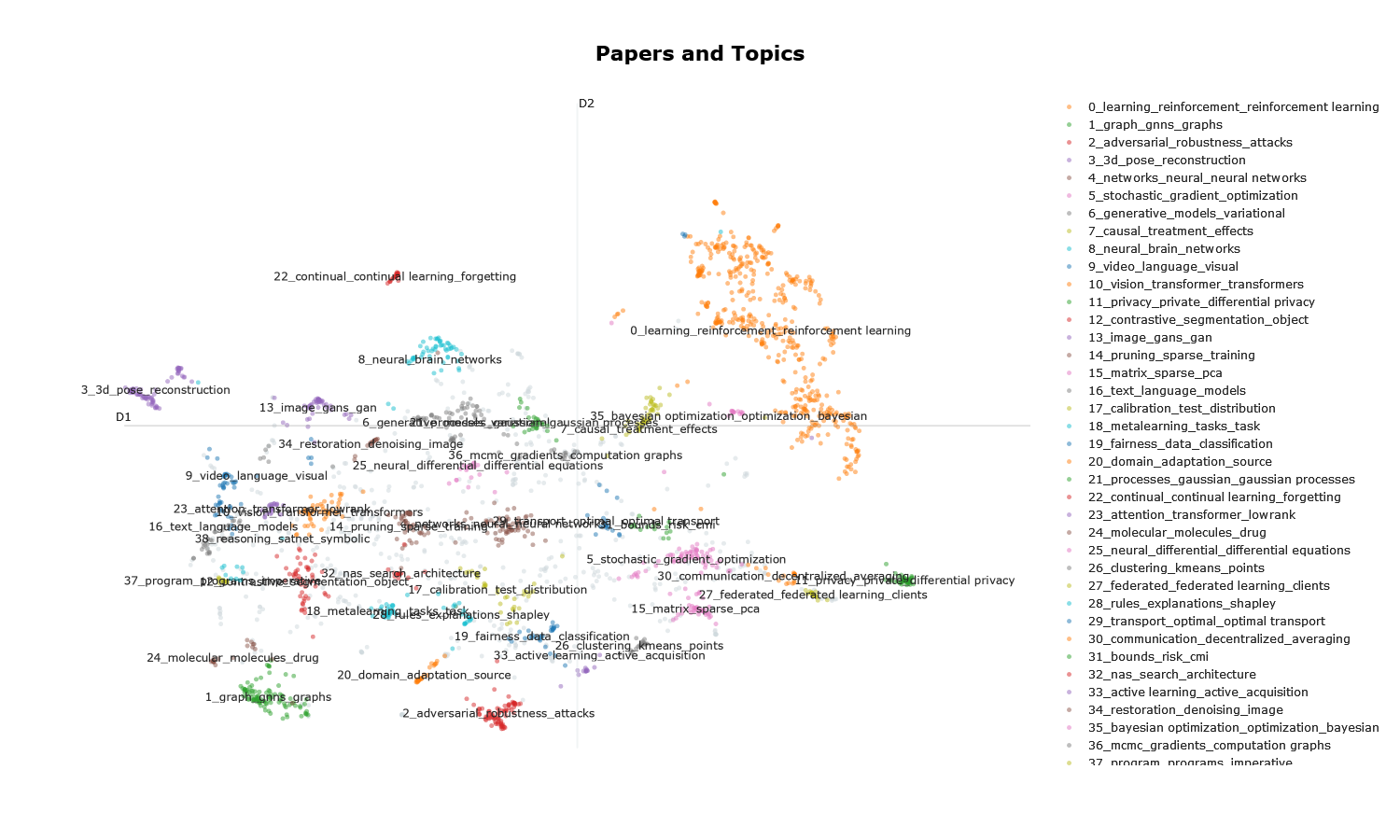
Given the deluge of research papers in AI, one often needs to (re)orient themselves to keep up with the latest and greatest—not to mention the “state-of-the-art”— developments, all the while exploring new and exciting research avenues.
But what if we could have a bird’s-eye view of, say, conference papers for example? With modern language models now able to fully parse and capture contextual semantics from text, we can finally resolve this information density problem and break away from the classic scroll-through-a-table for exploration. Think of it more as visual literature review.
Neural Topic Modeling (NTM) approaches such as Top2Vec [1], CombinedTM [2] and BERTopic [3]—to name a few—have been gaining traction recently [4], and we could use one such approach to cluster documents in an unsupervised manner with minimal preprocessing.
For this experiment, I decided to go with papers accepted at NeurIPS (2021). Here’s a preview of what the dataset (scraped from the site) looks like below:
| Title | Authors | Year | Abstract |
|---|---|---|---|
| Beyond Value-Function Gaps: Improved Instance-... | Christoph Dann, Teodor Vanislavov Marinov, Meh... | 2021 | We provide improved gap-dependent regret bound... |
| Learning One Representation to Optimize All Re... | Ahmed Touati, Yann Ollivier | 2021 | We introduce the forward-backward (FB) represe... |
| Matrix factorisation and the interpretation of... | Nick Whiteley, Annie Gray, Patrick Rubin-Delanchy | 2021 | Given a graph or similarity matrix, we conside... |
| UniDoc: Unified Pretraining Framework for Docu... | Jiuxiang Gu, Jason Kuen, Vlad I Morariu, Hando... | 2021 | Document intelligence automates the extraction... |
| Finding Discriminative Filters for Specific De... | Liangbin Xie, Xintao Wang, Chao Dong, Zhongang... | 2021 | Recent blind super-resolution (SR) methods typ... |
| ... | ... | ... | ... |
2334 rows × 4 columns
So, let’s briefly define our goals below:
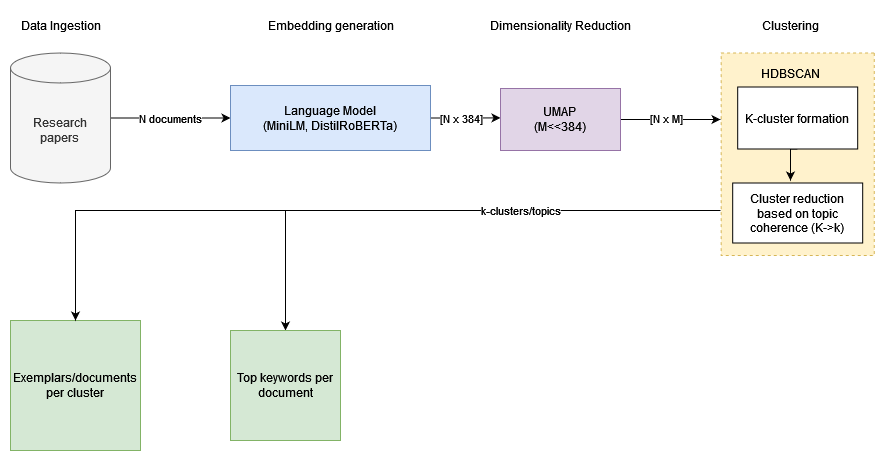
- We need to obtain a relevant dataset of papers and concatenate their
title+abstract, which will serve as our corpus (of sizeN) - For topic/cluster discovery (à la BERTopic):
- Use a pre-trained language model (for faster inference: MiniLM or
all-MiniLM-L6-v2with SentenceTransformers [5]) to embed documents into aN x Mdimensional matrix - Use UMAP [6] to obtain a low-dimensional projection, and
- HDSCAN [7] for clustering
- Use a pre-trained language model (for faster inference: MiniLM or
- Find salient clusters
- Identify interesting research papers/directions
Once we perform the steps above, we end up with the interactive 2D clusters here.
Few (personal) takeaways:
- Reinforcement learning (RL) dominates a lot of the space (~\(21\%\)).
- Graph Neural Nets (GNN) are the second most prominently featured area (~\(5\%\)), followed by adversarial attacks, gradient-based optimization and 3D Pose Reconstruction.
- Language models (including topic modeling) occupy a sizeable area.
- Transformers have fully anchored itself across video, text, audio and images.
- GANs are still in the game (although this is likely to change—with Diffusion models having a massive surge this year).
- There’s a surprising amount of neuro-inspired and related deep learning papers (under
neural_brain_networks). - Quite a few papers on calibration methods for deep neural nets.
- Sparsity and pruning in neural nets is still an active area of research (under
pruning_sparse_training).
I encourage you to explore and find areas of your interest(s) among the clusters. Alternatively, feel free to experiment with your dataset of choice (in the notebook) to discover latent clusters.
Note:
- A typical language model has the constraint of maximum sequence length (
256, in case of MiniLM) that it can process, and beyond which the input sequence/text will be truncated. - The clustering phase largely depends on two important hyperparameters: number of neighbors (UMAP) and minimum cluster size (HDBSCAN). It is always advisable to try a few different values, or alternatively use topic coherence measures (NPMI, for example) for cross-validating the optimal values for the same.
References
[1] Angelov, D. (2020). Top2vec: Distributed representations of topics. arXiv preprint arXiv:2008.09470.
[2] Bianchi, F., Terragni, S., & Hovy, D. (2020). Pre-training is a hot topic: Contextualized document embeddings improve topic coherence. arXiv preprint arXiv:2004.03974.
[3] Grootendorst, M. (2022). BERTopic: Neural topic modeling with a class-based TF-IDF procedure. arXiv preprint arXiv:2203.05794.
[4] Zhao, H., Phung, D., Huynh, V., Jin, Y., Du, L., & Buntine, W. (2021). Topic modelling meets deep neural networks: A survey. arXiv preprint arXiv:2103.00498.
[5] Reimers, N., & Gurevych, I. (2019). Sentence-bert: Sentence embeddings using siamese bert-networks. arXiv preprint arXiv:1908.10084.
[6] McInnes, L., Healy, J., & Melville, J. (2018). Umap: Uniform manifold approximation and projection for dimension reduction. arXiv preprint arXiv:1802.03426.
[7] McInnes, L., Healy, J., & Astels, S. (2017). hdbscan: Hierarchical density based clustering. J. Open Source Softw., 2(11), 205.